The Unstructured Data Problem?
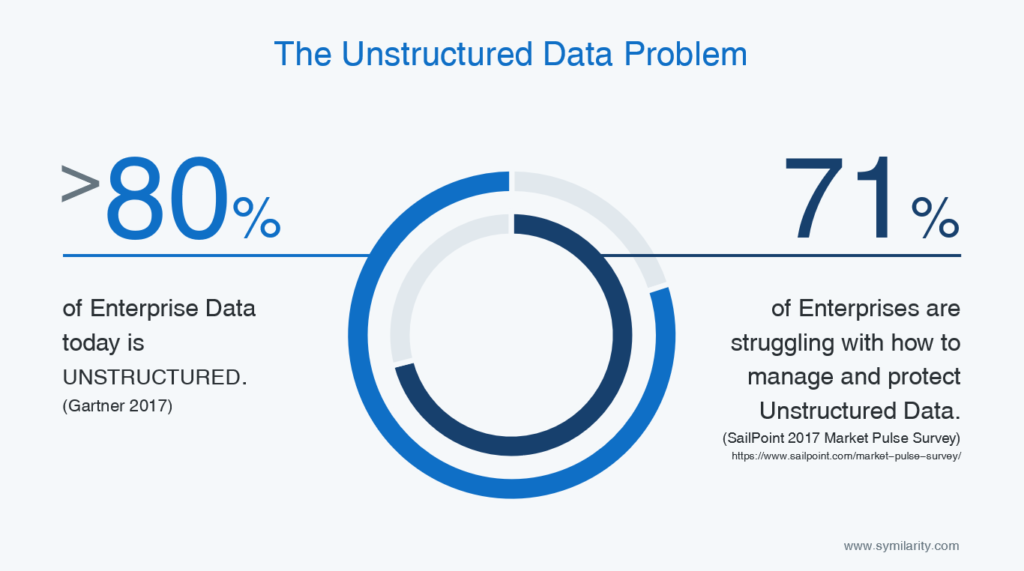
Most data within our enterprises today is unstructured. It exists in word documents, excel sheets, PDFs or data logs from other processes. Analysts Gartner estimated in 2017 that 80% of the data footprint of an organisation is unstructured. They went on to indicate that this would increase by 300% within a few years and that much of this data would be created outside the datacentre.
The Implications
We know, if we want to find information within a large structured database, there is usually a simple query screen that will find the results we are looking for. However, the size and growth of unstructured data presents many problems to organisations:
- De-Centralised: Information that is important to the organisation is not necessarily stored where it can be found by those that need it.
- Non-uniform: The data is in many different file formats and the data within each document is not arranged in neat fields
- Scale: The large number of documents means even a good filing system is going to be difficult to manage
- Hard to Query: The unstructured nature of the data means that finding specific information within the documents takes time and effort.
Why try and solve the problem?
There are two key reasons for trying to solve this problem:
Efficiency/Productivity
Searching for information is a key part of an employee’s work life. In 2012, McKinsey estimated that an employee can spend nearly 20% of their productive work time looking for information. It can take 1-2 years for new employees to become fully productive, so making information easier to find makes employees more productive and reduces training time.
Hidden Value
The data contained within this unstructured documents is valuable. It contains information that is key to the business in terms of existing knowledge but it also contains untapped information that could improve the organisation if suitable business intelligence tools can be applied.
How can Symilarity’s Helix Enterprise Search/Insight Engine help?
Symilarity’s Helix Enterprise Search/Insight Engine provides a centralised store for an organisation’s data and provides extraction, enrichment and search functionality to help organisations gain the efficiencies and tools to extract value from their unstructured data.
Repositories
Helix is based on the concept of repositories. Repositories are user defined containers that hold indexes for the ingested data. These can be departmental, project based or chosen in any way that benefits the organisation. Permissions to access data are held at a repository level.


Ingestion
Helix ingests all common document formats including MS Word, PDF, Excel, PowerPoint, Plain Text, Html and Mhtml, CSV and XML.
Documents can be ingested one at a time, in small groups or as a large batch as part of an automated process.
In addition, Helix also supports the ingestion of RSS feeds and data mining of specified websites.
Extraction and Enrichment
Helix provides multiple types of extraction and enrichment. These include:
- Entity Extraction (People, Places, Organisations)
- Geocoding of extracted place names
- Subject Verb Object identification
- Sentiment calculation
- Topic Categorisation
Mining of websites will also extract keywords based on user selected algorithms. Extracted and enriched data is held in separate fields to the original data.


Search
Helix provides significant search capabilities including:
- Ability to search across multiple repositories (federated search) or individual fields
- Ability to filter search results based upon faceted fields or tags
- Unsupervised machine learning (Vector Space Modelling) providing more relevant search results
- Ability to find similar documents to a chosen document
- Enhanced free text results including fuzzy matching, term proximity and boosted search results
- Ability to search spatially based upon the coordinates of the extracted place names
Analysis and Discovery
Helix provides many tools that can be applied:
- Word Frequency Analysis and comparison
- Word Cloud visualisation
- Document Clustering
- Principal Components Analysis and visualisation
- Entity and relationship extraction to a graph database

Symilarity’s Helix Enterprise Search/Insight Engine provides a centralised store for an organisations data and extraction, enrichment and search functionality to help organisations gain the efficiencies and tools to extract value from their unstructured data.