The Discovery Process – How to Investigate a Large Document Corpus of Unstructured Data
Discovery and the Unstructured Data Problem
How would you investigate a large corpus of unstructured data? Firstly, why might this be important? Many jobs, with a research or investigation component, start by gathering data. This can be from internet search, colleagues or is the data associated with the case being investigated. This data usually has some connection to the task but without reading a document in full, you don’t know how relevant it might be. Reading them all may be required but it might be better to get a sense of the whole before diving into the detail. An understanding of the whole corpus provides context for understanding the detail. It might also highlight patterns or an emphasis in the data that can be explored in the detail and which might have been overlooked if the pattern was not identified.
The Challenge
Given 1,000 documents, how would you go about understanding what is in them, without trying to read them all? Well, here are some suggestions that are all supported by Symilarity’s Helix Insight Engine.
1. Word Frequency
We can analyse the frequency of each word used within the document set. This tells us something about the most common words used in the set and also the least common. It also tells us something about the range of words (i.e. the type of vocabulary) used.
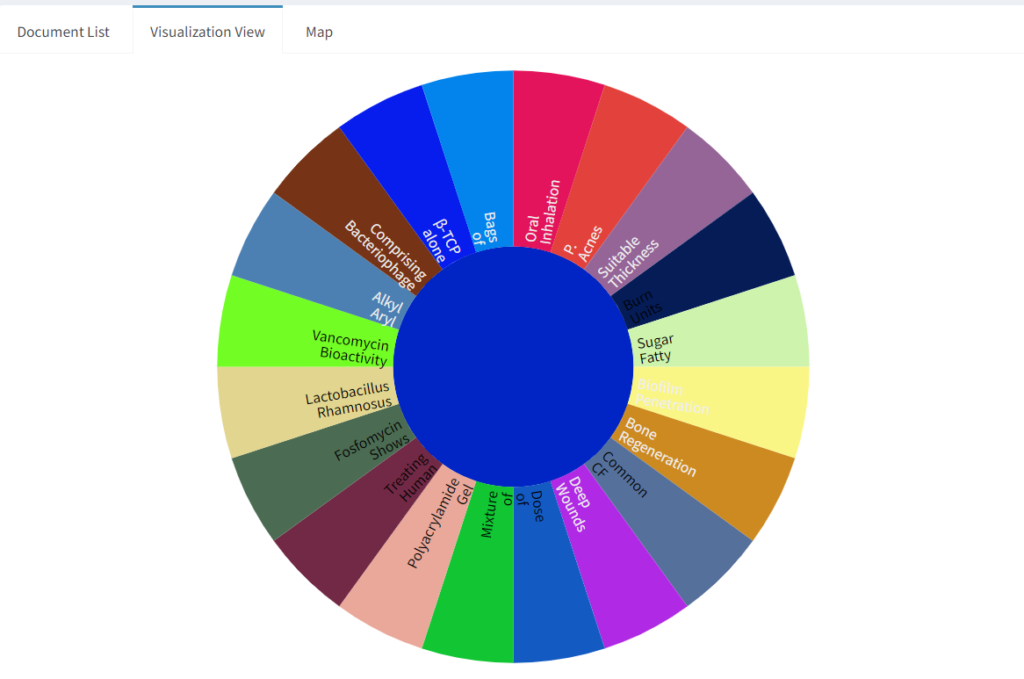
We can look at word frequency as a bar chart but also as a word cloud. Whilst a word cloud might not look very like a very scientific mode of communication, it is easy to assimilate. Have a look at the one on the right and see what type of documents it relates to (answer at the bottom of the page).

2. Classification
We can use a large pre-trained classifier to tell us about the topics referenced in the documents. Services like Watson Natural Language Understanding (NLU) provide this type of classification/categorisation service.
3. Clustering Snippets from Search Results
We can search within the corpus and cluster the snippets from the search results to give us some clues about the other data within it. The image below shows the clustered snippets for the search term “antibiotics” within a corpus of 8,000 medical/veterinary patent applications. The snippet is the text surrounding the search term and shows the context in which it is used. The clusters have meaningful labels giving some insight into the topic within.
4. Clustering Documents
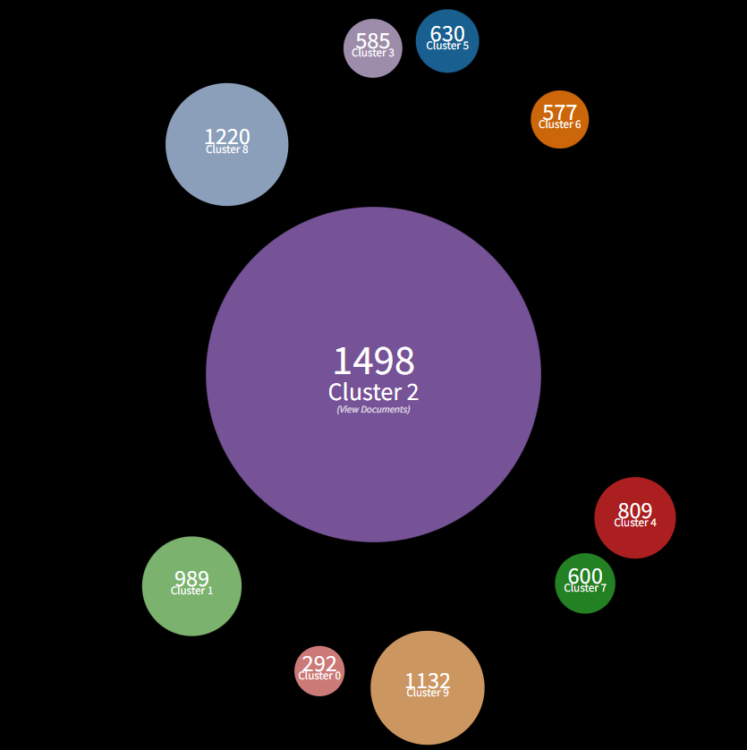
We can use Vector Space Modelling to split the corpus into clustered groups. Here we have split a corpus of 8,000 medical/veterinary patent applications into 10 clusters. This allows us to examine sample documents from each cluster to explore the commonality between documents within the cluster and the differences between clusters.
5. Network Analysis
We can process the documents using natural language programming techniques, to extract the places, people and organisations mentioned within the text. We can also take this further to extract the relationships between those entities and show them as a network.
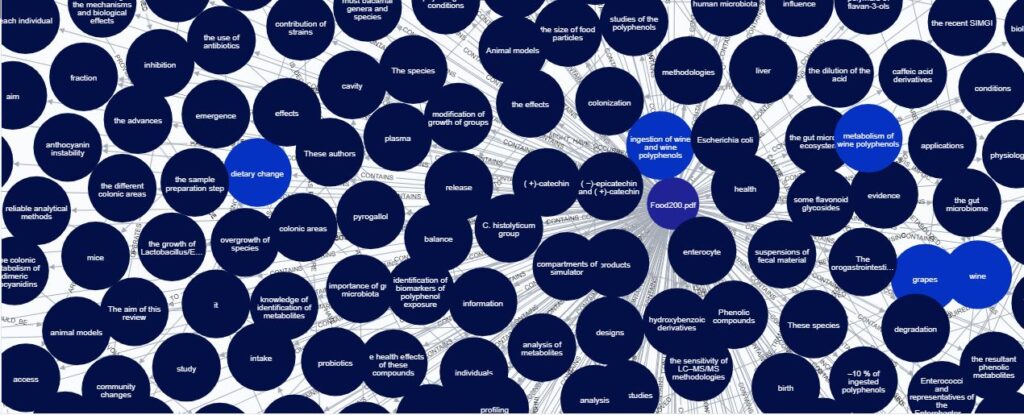
The data above has been derived by processing academic research papers on the Human Gut Biome.
6. Location
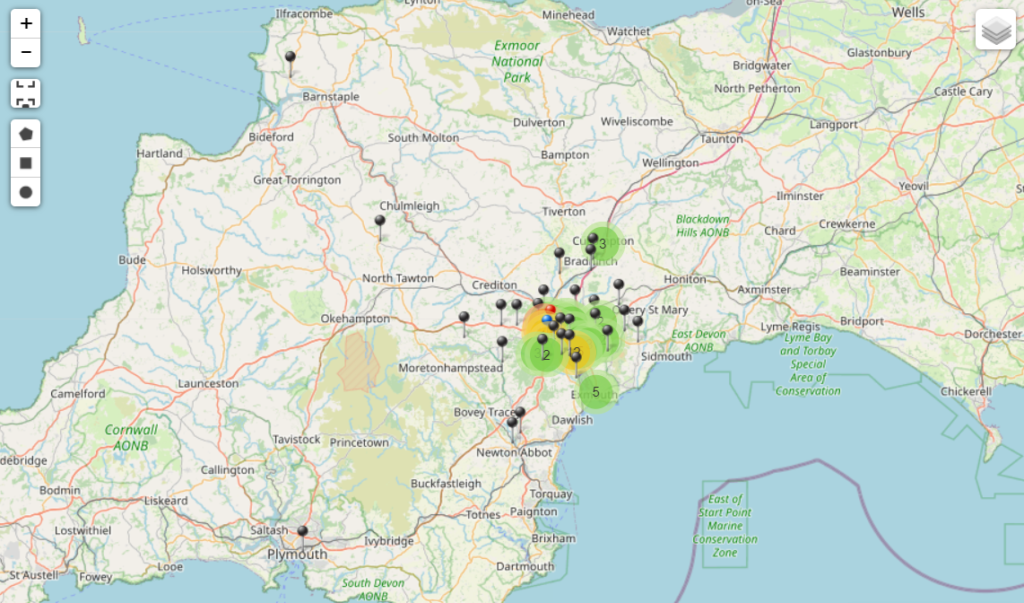
As a subset of the Natural Language analysis, we can consider all the place names referenced in the document set. This requires assigning coordinates (latitude and longitude) to all the extracted place names, then visualising them on a map.
7. Vector Space Modelling – Term Similarity
Vector Space Modelling is a technique that uses the occurrence of words in documents to create a statistical relationship between each word in the document set. This technique enables you to see the words (Terms) that are most closely related to each word used in the document set. For instance, if in your investigation of the dataset, you encounter an interesting word, you can use term similarity to identify other words that are related to it. This provides two powerful capabilities:
- You can get a sense of the diversity of the dataset by the diversity of the terms (i.e. if the terms are closely related, the content of the documents must also be closely related)
- You can use the terms and their related terms as a way to browse the content, find interesting content and then identify related documents.
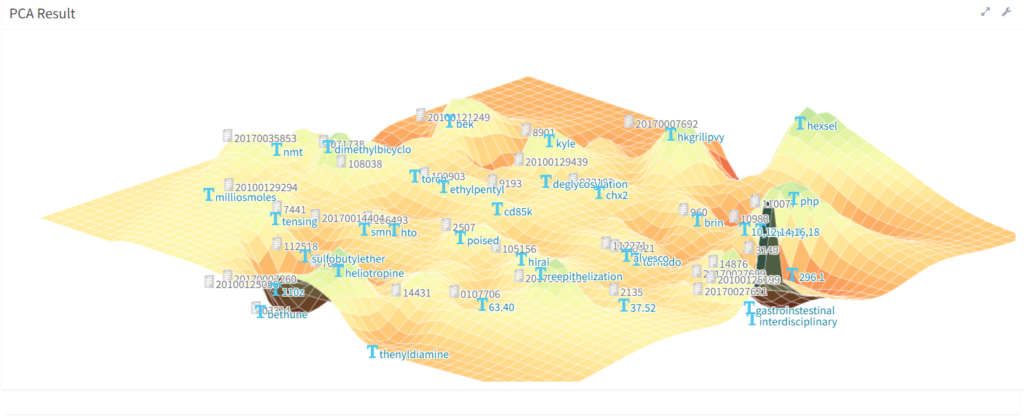
8. Principal Component Analysis
Finally, a more unusual approach is to use Principal Components Analysis (PCA). This technique provides a way of looking at the variability and relatedness of the data. Here we have a 3D surface visualisation of medical/veterinary patent applications showing the documents and terms at key points on the surface. The model allows for the surface to be explored interactively.
Answer to word cloud: The word cloud was created using a corpus of CVs.